jBPM 6.3.0.Final has been released !
In this release we focused on bringing a bunch of (typically smaller but powerful) features that our users were asking for. A quick highlight is added below, but full details can be found in the release notes.
To get started:
jBPM 6.3 is released alongside Drools (for business rules), check out the new
features in the Drools release blog.
Thanks to all contributors!
Core engine improvements
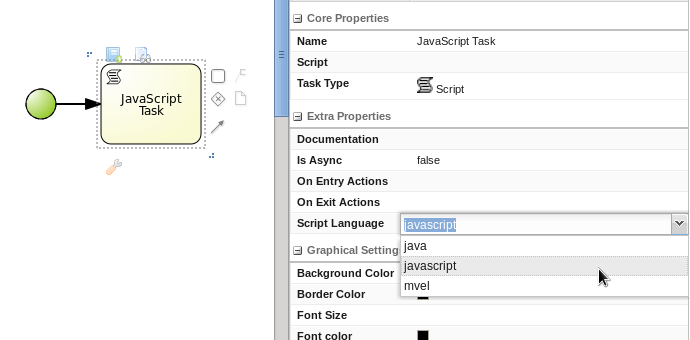
- Support for JavaScript as script / constraint language in processes
- Asynchronous processing improvements, including
- the (re)introduction of asynchronous continuation (where you can mark a transition as to be executed asynchronously in a separate transaction)
- ability to mark signal throw events as asynchronous
- jbpm-executor (our asynchronous job executor) got configurable retry mechanisms and improved performance due to new JMS-based triggering
- Signal scopes for throwing signal events, so you can better decide who the event should be sent to (process instance, ksession, project or external)
Configurable and extensible task and process instance list
- Custom filters:
The process process instance list and task list in the workbench can now be configured even more by the end user by adding custom filters. This allows you to create new tabs that show a subset of your tasks (or process instances), based on parameters you decide yourself.
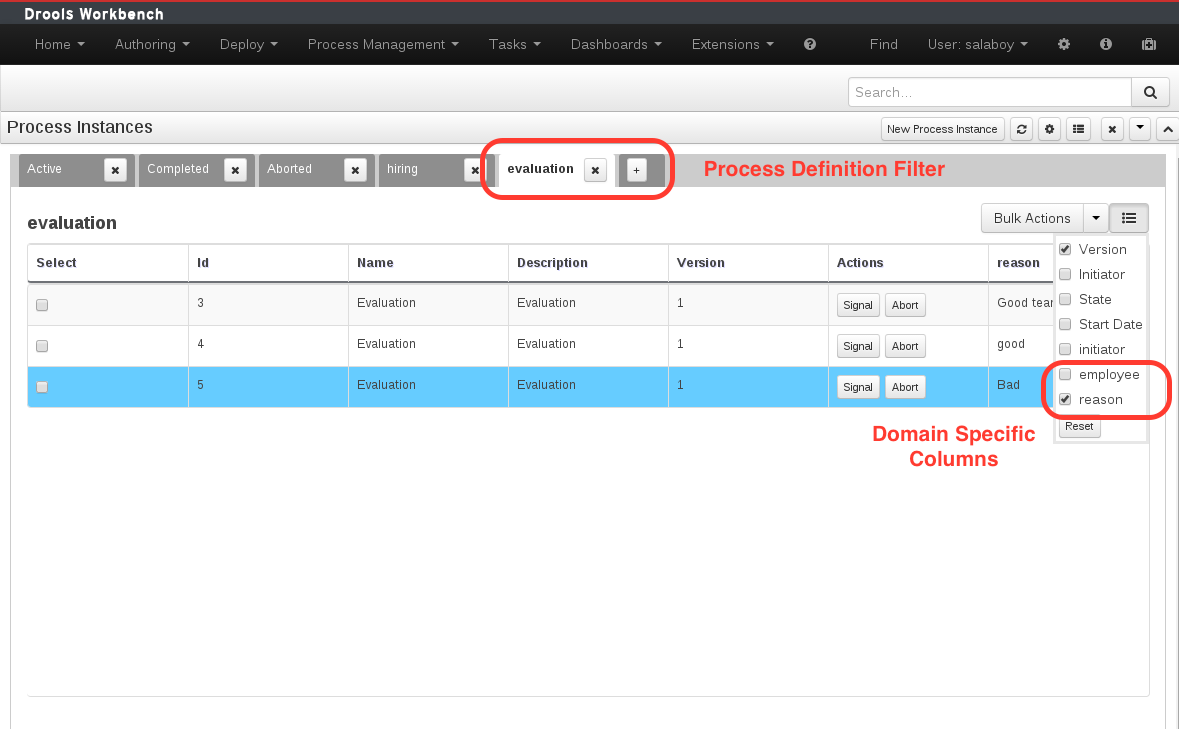
- Domain-specific columns in the process instance list
You can show now show (domain-specific) data related to the process instance variables in the process instance table directly, by creating a custom filter that restricts the data to one specific process. Doing this allows you to then add domain-specific columns: additional columns can be added to the table that show the value of variables of that specific process.
Data mapping in Designer
When you have a lot of data being managed in your process, defining the data flow among all the nodes can become pretty complex. A new data mapper has been added to Designer to simplify this task: it has the ability to do all you might need in one place (like adding new data inputs / outputs while you've already started doing the data mapping) and simplifies data assignments (either by giving a direct value or by mapping an existing variable).
Embeddable process / process instance image
New operations were added to the remote API to allow retrieving the process image or annotated process instance image (showing which nodes are active / completed). This image is similar to the one you were already able to access inside the workbench already, but is now also available remotely for embedding in external applications.
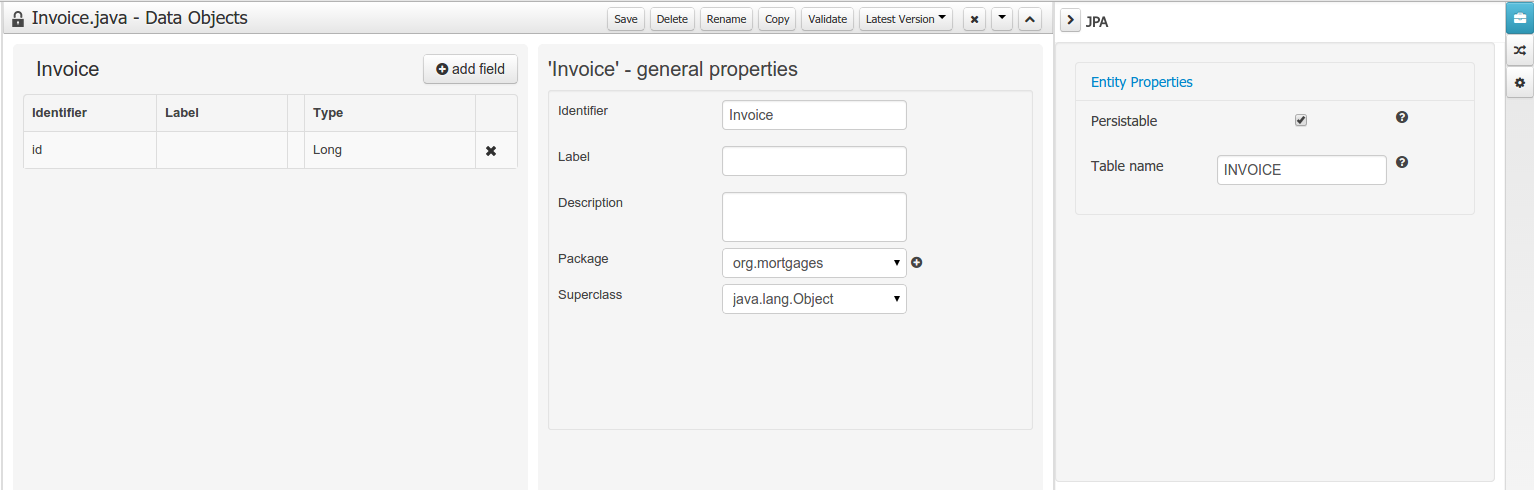
JPA support in the Data Modeler
The data modeler in the workbench now also exposes properties that allows you model a data object as a JPA entity. When a data object is modeled as a JPA entity, it is not stored as part of the process instance state but stored in a separate (set of) database table(s), making it easy accessible from outside as well.
Case management API
The
core process engine has always contained the flexibility to model
adaptive and flexible processes.
These kinds of features are typically also required in the context
of case management. To simplify picking up some
of these more advanced features, we created a (wrapper) API that
exposes some of these features in a simple API: process instance
description, case roles, ad-hoc cases, case file, ad-hoc tasks, dynamic
tasks and milestones.
Support for these features in our workbench UI is being worked on for version 7.0.
Unified execution server
A lot of work went into the creation of
unified, highly configurable, minimal execution server - ideal for cloud-based or micro-services architectures. Since v6.0 the workbench has included an execution server that could be accessed remotely. This was however embedded into the workbench and designed to operate in a symmetric way when deployed in a clustered environment (all nodes in the cluster were able to execute all processes / requests). In Drools v.6.2 a new minimal decision service was introduced that allows only deploying specific rule sets to specific containers, giving the user full control over deployment. This has now been unified, resulting in a
lightweight execution server where you can execute your processes, rules, tasks and async jobs. It can be set up as a single execution server for all your projects, or different execution server instances (possibly one for each project).